Data Warehousing Data Mining And Olap Alex Berson Pdf Editor
Data_warehouse levselector.com New York > Data Warehouse Data Warehousing, OLAP & Reporting. On This Page: Other Pages: - - - - - - - - - - - (Executive Information Systems, Decision Support Systems, Statistics and Technical Data Analysis, Neural Networks, End-User Query and Reporting, Data Warehousing, Mapping and Visualization, Data Mining and OLAP, ) Operations vs Analysis - - Let's distinguish between databases optimized for 2 types of work: operations and research. -- operational processing - OLTP(On-Line-Transaction-Processing) Research and Analysis - DSS (Decision Support System), OLAP (On-Line-Analytical-Processing), Data mining Optimized for inserts, updates, and deletes queries Frequency of updates Frequently (may be every second) Usually once a day. Data for analysis is prepared once a day (at night) at a staging area, then loaded into the main OLAP database - and then used during the day.

Vectorworks 2014 serial number crack. Wavelab 7 dongle crack download. Number of indexes Few indexes Many indexes Level of normalizing the database Normalized to some reasonable degree Heavily de-normalized for easier and faster querying Some analysis (for example, Multi-Dimensional Analysis) is really much better done using instead of standard RDBMS. Star schema & Snowflake configurations - - One of the difficulties of querying a normalized database is in the big number of tables you may need to join sequentially in one query.
Data Mining: Concepts and Techniques.
You can easily have to chain 10 and more tables. This is difficult for a user (he must know his tables really well), and it may have very poor performance.
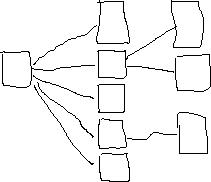
Or even crash the database. The common approach to resolve this problem is to try to restructure the data. You denormalize your tables. You also restructure them into so-called 'star'-configuration to avoid long chains. This means that you create one big 'facts' table (the center of the star) surrounded by 10-15 'dimension' tables.
This way you avoid long chains. Then you basically query one central 'fact' table - and narrow your scope by joining it with some 'dimension' tables. Your chain length =1. Sometimes you may add extra 2-nd layer (chain length=2 - details) - this is called the Snowflake configuration - see images: Star Configuration Snow Flake Configuration The Star Schema is also known as a ' star-join schema', ' data cube', and ' multidimensional schema'. The main benefit of Star schema configuration is that it makes easy for users to to make reports/queries, especially implementing multi-dimensional views of data with different granularity for different dimensions. The applications (reports) become simplier and easier to understand for the user. • Fact table - usually contains 'facts' of events involving dimensions.
For example, a purchase may be considered as a fact, which is characterized by many dimensions (time, store, product, promotion, etc.). Thus a row in a fact table corresponding to one purchase will have foreign keys to all corresponding dimension tables. The fact table stores the data at the lowest level of granularity, for example, for time dimansion the granularity may be - seconds. The other levels of granularity (hour, day, week, month.) are stored in corresponding 'dimension' table.